Semantic Data Model: The Blind Spot Holding Back Your AI Agent

Obviously, large language models (LLMs) are incredible. Type a couple of lines like you’re texting your mom and out comes a well-researched article, functional code, or a photorealistic image in seconds. It’s easy to see why McKinsey, Deloitte, and everyone else project them to cause trillion-dollar shakeups in the business world.
But LLMs are running into a wall — especially when companies try to use them in applications at enterprise scale. What’s the problem? They need a semantic data model — a way to structure and connect data so AI can understand and use it effectively.
Why LLMs are struggling with private data
ChatGPT, Claude, Gemini, and a few other LLMs can give great answers to questions like:
“What is the chemical structure of caffeine (and why do I love it so much)?”
“What is a highly rated place for lunch near the Roman Colosseum?”
“If there’s something strange in your neighborhood, who you gonna call?”
But they completely whiff business questions, like “What’s the current issue with Acme Corp., and have they paid their bill this month?”
Why is that?
It’s because LLMs (like other AI models) only know what’s in their training data. That training data is enormous, but it’s not everything. ChatGPT doesn’t know any of your company’s private data just like it doesn’t know what you ate for breakfast.
But it needs to use your company’s data to generate outputs that are actually useful for your business.
You can get around that problem on a one-off basis by pasting or uploading some of your data with your prompt. But that doesn’t scale. If you envision an AI-powered workflow for a 10,000-person company, it can’t get bogged down by each user manually uploading PDFs every time they need an answer. You need your application to ingest your data and work on it in a programmatic way.
It’s not as simple as just connecting your database through an API and letting an LLM have at it. Customer order history, product usage, account details, and most of the other information you need to make decisions are all structured data. LLMs can’t process this type of data well. They’re configured for unstructured data — text, images, audio, and videos.
If you give an LLM a relational database like the ones you use to store most of your data, it doesn’t know what to do with it. It can read all the cells, but it has no sense of the relationship between any of them — or the relationship between one database and another. Humans can figure this stuff out easily, but LLMs can’t.
This hiccup creates a huge stumbling block that keeps LLM-based applications from finding traction. ChatGPT is great for individuals, but enterprises aren’t rolling out company-wide implementations of ChatGPT workflows.
For enterprises to reach the level of AI transformation that has all the trendspotters drooling, LLMs need a way to understand the meaning and relationships behind your company data — and do it across the hundreds or thousands of databases that big companies trust every day.
Fortunately, smart data engineers have figured out how to do it. Meet “semantic data models.”
What is a semantic data model?
A semantic data model is exactly what it sounds like: a model of your data that holds the meaningful (aka “semantic”) relationships between all your data points.
These models are implemented through a format called a knowledge graph (more on that later). These knowledge graphs sit between your application frontend and your LLM, providing information about how all the data in your entire collection of databases relates to each other — almost like a meta-database.
Every company has a huge collection of customer data in several places:
Customer relationship management systems (e.g., Salesforce)
Customer support software (e.g., Zendesk)
Marketing automation platforms (e.g. HubSpot)
Communication software (e.g., Slack or Microsoft Teams)
Any one of these databases may have thousands of tables, columns, and rows, amounting to millions of cells.
That’s just for customer teams. Companies also have project management tools, accounting systems, document management systems, and many more databases. Humans can readily understand the relationships that underpin this data. They can easily see that “Start Date” in one table refers to “init_date” in another. They know that an account number stored in a table means the same thing when it appears in-line in a contract PDF.
But LLMs can’t. They’re not built for those kinds of semantic leaps. To connect the dots, they need a structure that maps out the meaning behind all the interrelated data across all your databases. That’s a semantic data model.
Ontologies, semantic data models, and knowledge graphs — what’s the difference?
When you start looking into the world of knowledge representation, things can get super confusing, super fast. Read any article and you’ll see terms like “ontology,” “semantic data model,” and “knowledge graph” more often than an undergrad philosophy paper.
These terms are similar, but they’re not 100% the same. Here’s a useful way to think about them.
Ontology is the conceptual framework for how your data relates to each other. It sets out the entities, the attributes, and the relationships. Your ontology establishes the meaning behind the data and the rules for how all the parts play together.
A semantic data model is the structured representation of that ontology. It’s how you organize your data relationships, arranging them in a way that reflects their meaning.
A knowledge graph is the construction of a semantic data model in an actionable format. Knowledge graphs assemble all the entities, their attributes, and their structured relationships in a machine-readable format — like a graph database — so AI applications and other computer systems can use them.
Still confusing? Think of a library:
The ontology is the idea and principles of librarianship — books, periodicals, Blu-rays, etc.
The semantic data model puts those concepts into a meaningful structure — like the Dewey Decimal System.
The knowledge graph is like your local library — an actual implementation of the model, where you can go and act on it (by checking out books).
Note: It’s important to explain a nit in terminology here. Palantir is a major leader in establishing semantic data relationships as part of technological systems. They often refer to their “Ontology” as a core component of their platform. While the idea is similar, Palantir’s use of “Ontology” refers to a practical application that does the semantic mapping within their data ecosystem — not the ontology explained above. I know.🫣 It’ll be OK.
‘Doesn’t RAG already give LLMs this contextual information?’
Sadly, companies can’t RAG themselves out of this knowledge mapping problem.
Retrieval-augmented generation (RAG) certainly gives LLMs additional context for their responses. It’s a super useful way to make LLMs more useful for business too. But there’s one problem: RAG only works with textual data like emails, meeting notes, or corporate policies. It doesn’t do anything for structured data, like Salesforce, Zendesk, or internal SQL databases.
RAG pipelines are also limited to exchanges between you and your LLM. They don’t resolve the problem of giving your model detailed functional knowledge of the relationships that underpin your data. RAG is essential for certain AI applications, but it’s the wrong tool for establishing a semantic layer across your data ecosystem.
It’s like a hammer when all you really need is a map to the location of your tools.
How does a semantic data model improve information retrieval?
While semantic data models are foundationally different from RAG, they both do the same thing: provide additional context to LLMs. Semantic data models just do it in a different way. (If you want to know how RAG works, check out our post all about it: The Easiest Way to Understand RAG.)
Imagine you have a chatbot to help with customer support. You receive a new support ticket that says a dashboard in your product isn’t updating right. You copy and paste that information into your chatbot along with a question, like “What’s the current issue with Acme Corp., and have they paid their latest invoice?”
If you’re just using an LLM, you’ll get an answer — it just won’t be useful (even if you have it connected to Salesforce, Zendesk, or any other structured database). That’s because the LLM doesn’t understand how your data fits together.
If you had enough time, you could copy and paste enough data into the chatbot’s context window and provide detailed instructions about how it all works. It might be able to figure out which fields in one table correspond to other fields in other databases if prompted right. But the LLM can’t do that on the fly across thousands of databases. When you prompt your LLM, it will still return an answer — probably a convincing one — but the answer won’t have anything to do with your actual data. It will just hallucinate a response out of thin air. Unless your customer support representatives know better, they’ll trust the LLM’s response and take action on complete nonsense.
But everything’s different with a semantic data model in the mix. LLMs then have a structure to follow to draw on key concepts and how they relate to each other. When you submit a prompt, an LLM can check the model to determine the semantic structure of your data. In the case of Acme Corp., the LLM would see that “Acme Corp.” is the company name, so it could associate the “Account Name” field in Salesforce with the “Organization Name” field in Zendesk. It would know the account number, so it could link support tickets in Zendesk to invoice records in your SQL database. It could link payment history dates to account health statuses in Salesforce. Everything becomes tied together and explained.
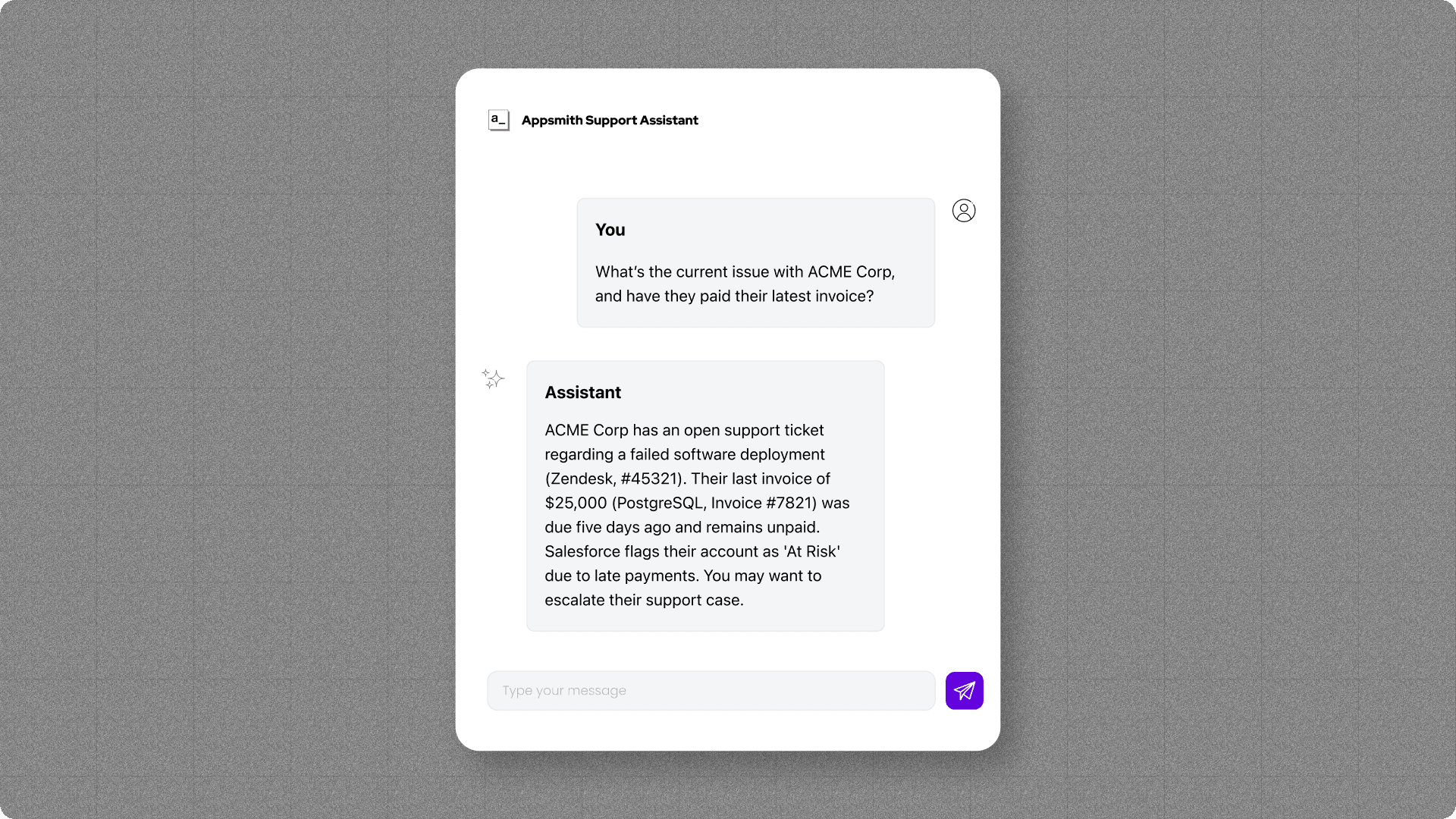
Now when you ask the chatbot, “What’s the current issue with Acme Corp., and have they paid their latest invoice?” your application can:
Retrieve the open support ticket for Acme Corp. from Zendesk.
Check the status of the company’s latest invoice in your PostgresDB.
Determine if Acme Corp.’s account is at risk based on fields in Salesforce.
Use the LLM to synthesize all that data into a single, tailored response that your customer support team can send back to the customer.
Without that semantic data model to put meaningful order to everything, who knows what kind of gobbledygook the LLM will generate?
How do I incorporate a semantic data model into my AI application?
It’s clear that if you’re building an application that relies on an LLM to sync with your own structured data, you need to include a semantic data model. But how?
The answer is knowledge graphs. As mentioned above, knowledge graphs put your semantic data model into a format that computer systems can use. Neo4j is a popular graph database that Appsmith supports to make your semantic data model a reality. Watch our video all about knowledge graphs below.

If you’re used to relational databases, you’ll notice that graph databases are a bit different. While they both store data, graph databases like Neo4j don’t use the standard tables, rows, and columns. Rather, they store data as “nodes” — and each node represents an entity, like a customer name or an account number. The relationships between nodes are represented as “edges,” which reflect connections between some nodes (and missing edges represent disconnections). The data takes the shape of a network more than a rigid table, making it a closer model of messy, real-world relationships.
Because those connections are prioritized in a graph database, queries that concern relationships occur much faster than in a relational database.
Once a knowledge graph is integrated as part of an application workflow, then your team can simply connect an LLM and give it instructions on how to leverage the knowledge graph in its inferences. Prompts can trigger your query engine to search the knowledge graph for relevant data and send it to the LLM, so its outputs are more accurate and it doesn’t literally make things up as it goes along.
What challenges exist in implementing a semantic data model?
Easy, right? Throw a knowledge graph into your application workflow and “Boom!” Instant context for your LLM responses!
Yes and no.
Once you have a knowledge graph, it’s no sweat to use it as part of your AI application. If you’re using Appsmith, you can do it in literally 30 seconds.
But building a comprehensive knowledge graph of your entire data ecosystem is no easy feat. It can take months of planning, discovery, architecture, development, testing, and integration. It requires highly skilled database engineers to construct it and apply it effectively. Once your knowledge graph is deployed, your job’s not over. You still need to maintain it — an ongoing process as your company expands, new technologies come online, and your data ontology becomes more and more complex.
Merging structured and unstructured data
Using both structured and unstructured data adds another challenge. It’s comparatively easy to link columns in structured databases because they have the same basic format. But blending database cells with strings, numbers, and other data types as they appear in text, images, audio, or video is more complicated. It involves extensive analysis and disambiguation to tell the LLM that, say, “Jordan” in a Country field always refers to the Middle Eastern nation and “Jordan” in a paragraph may mean the country, a person’s name, a river, or a basketball sneaker.
Performance trade-offs
Performance trade-offs also make things tricky. Applications that have only simple knowledge graphs are fine, but huge knowledge graphs can make it difficult for a query engine to find the subset of data needed. If the response takes too long — 30 seconds as an upper threshold — users find the experience frustrating and may refuse to adopt the application. Large knowledge graphs also come with large numbers of computations. If the volume and cost of that compute gets too high, it puts the whole application in jeopardy.
The bright side: rapid hardware improvements
Fortunately, as companies come to rely on semantic data models, we’ll see more and more tools, frameworks, and processes for dealing with these issues. Computing power is always getting more robust and cheaper too. The advances in GPUs have outpaced Moore’s Law, and the Microsoft announcement about their improvements in quantum computing could kick off a whole other wave of computing efficiency, making it easier to put complex AI workflows with huge knowledge graphs into action.
Without a semantic data model, your AI is flying blind
Companies are gearing up for AI to reach a whole other level as agents start to autonomously interact with data, systems, and customers.
But LLMs are still not ready to act autonomously. They’re still too prone to hallucination to trust without regular human oversight. They need context piped in as part of a workflow or their outputs make as much sense as a David Lynch movie. They need a semantic data model.
Fortunately, knowledge graphs are ready and willing to hop on it. Without them, an LLM can only draw on its training data, which stunts its ability to do much of anything with your private data it has never seen before. The layer of meaning offered by a semantic data model — implemented as a knowledge graph — is the key to propping up an LLM-powered application (or team of AI agents) that would otherwise fall on its face.
Semantic Data Model and AI Integration: Frequently Asked Questions
What is a semantic data model?
A semantic data model is a structured representation of data that defines the relationships and meaning between data points. It enables AI and machine learning models to process structured data more effectively, reducing hallucinations and improving accuracy.
Why do AI applications need a semantic data model?
LLMs like ChatGPT and Claude struggle with structured business data because they lack an inherent understanding of relational databases. A semantic data model provides context by mapping how different data points relate across multiple databases, making AI-powered workflows more reliable.
How does a semantic data model differ from a knowledge graph?
A semantic data model defines relationships between data points, whereas a knowledge graph is an actual implementation of that model in a graph database. Essentially, a knowledge graph stores and executes a semantic data model, making data relationships machine-readable.
Does retrieval-augmented generation (RAG) replace a semantic data model?
No. RAG enhances LLMs by pulling in relevant unstructured text data (e.g., documents, emails), but it does not structure relational data. A semantic data model organizes structured business data (like CRM or ERP databases) in a way that AI can understand.
What are some real-world use cases for semantic data models?
Semantic data models are crucial in industries that rely on structured decision-making, including:
Customer Support: AI chatbots retrieve customer account info from multiple databases.
Healthcare: Medical AI integrates structured patient records across hospitals.
Finance: AI-driven risk assessment models connect transactional data with regulatory policies.
Enterprise AI Agents: AI-powered workflows process company-wide data in an intelligent way.
How can I implement a semantic data model in my AI application?
To integrate a semantic data model, follow these steps:
Define your data ontology – Identify entities, attributes, and relationships.
Structure your semantic model – Use frameworks like OWL or RDF.
Build a knowledge graph – Implement the model in Neo4j, Amazon Neptune, or another graph database.
Connect to AI systems in Appsmith – Enable AI-powered applications to query the model.
Optimize for performance – Ensure fast data retrieval and scalability.
What are the challenges in building a semantic data model?
Challenges include:
Data complexity – Mapping relationships across multiple, disparate databases.
Integration issues – Ensuring compatibility between relational and graph-based data structures.
Performance trade-offs – Large-scale knowledge graphs require high compute power.
Ongoing maintenance – Models need continuous updates as business data evolves.
What is the best database for implementing a semantic data model?
Graph databases like Neo4j, Amazon Neptune, and ArangoDB are commonly used to implement a semantic data model because they excel at storing and querying relationships between entities.
Can a semantic data model improve AI-generated responses?
Yes. A semantic data model improves AI reliability by providing structured, context-rich information. Instead of hallucinating answers, an AI application referencing a knowledge graph can retrieve factually correct and contextually relevant responses.


