Choosing an AI Tech Stack for Your Business: A Strategic Approach

Without the efficiency and operational benefits of AI, your business will fall behind your AI-powered competitors (if it hasn't already).
There are many applications of AI in any business, but we've only scratched the surface of what's possible. In order to unlock the full potential of what custom AI solutions can do for your business, you need to rethink your entire tech stack, identify how AI can enhance existing processes and create new opportunities, and experiment with new tools.
This article discusses the most important factors you should consider when building your AI tech stack, as well as how you can integrate emerging AI tools into your business.
Custom AI solutions for business: what’s the current impact?
Historically, front-end UI components like tables and forms have been the main points of interaction with web applications. These components are hard-coded during the development process based on the structure of the data and what the developer thought would be the best way to display it.
Unfortunately, that may not be the best way for the people who actually use the application. If a developer creates an internal web application for a large organization, different people in different roles might want to see the same data in drastically different ways. For example, a high-level leader might only want to see certain high-level KPIs and would consider other data as distractions, whereas someone in the marketing department would need highly detailed analytics to do their job well.
This can lead to awkward compromises and points of friction that everyone just accepts because they think there’s no better way. Fortunately, however, we believe that AI is bringing an entirely new kind of interactivity to web applications that will make this no longer necessary. By properly leveraging AI, users will be able to query and update data in new, flexible ways that break from traditional, rigid interfaces.
Currently, AI is being used within business apps in a relatively limited capacity. There are two main enterprise use cases in production today. One is copilots that help users interact with other complex tools, like GitHub Copilot, which can assist developers with programming tasks, and Microsoft 365 Copilot, which helps users interact with their documents. The other is customer support chatbots, which help answer questions and solve problems at a low level. As we move into 2025, we expect the sophistication of AI-powered applications to continue to rapidly accelerate.
What AI will bring in 2025 and beyond
Sophisticated AI assistants will soon become the central point of interaction with many applications. Chat interfaces will replace buttons and forms as the main drivers of interaction with a web application: you'll simply ask your AI assistant, in plain language, to create an entire dashboard full of charts, graphs, videos, and other assets populated with correct data from your internal systems to answer your questions with confidence.
You won't have to rely on your developers to adapt their code to your specific needs. They will instead provide you with the AI tools you need to create and adapt new dashboards and views into your business-critical data, however you want to see it. If you're concerned about inaccurate responses, you can ask the AI assistant to include citations and evidence for its claims so that you can quickly verify its output.
In short, AI will be able to answer your questions based on multiple datasources in many different formats like text, tables, JSON, charts, and many more. This opens up a huge number of avenues that didn’t exist before, while the data is still fresh and actionable. AI assistants will also transform the way users interact with your business externally and internally.
Externally, AI assistants will be able to provide the first line of customer support and route any questions they can’t answer to the appropriate customer support rep. This functionality is already operating in many companies, putting them ahead of their competitors by reducing support overheads while improving solution times and customer satisfaction.
Internally, new engineers can work with an AI assistant to set up a local development environment based on specific company documentation and have an assistant help them through training materials and practical onboarding tasks (as the AI will be aware of the company documentation).
What you need to know: The components you need for your AI tech stack
In order to power this future functionality, traditional web application tech stacks that have existed in more or less the same form for 20 years will need to be entirely rethought.
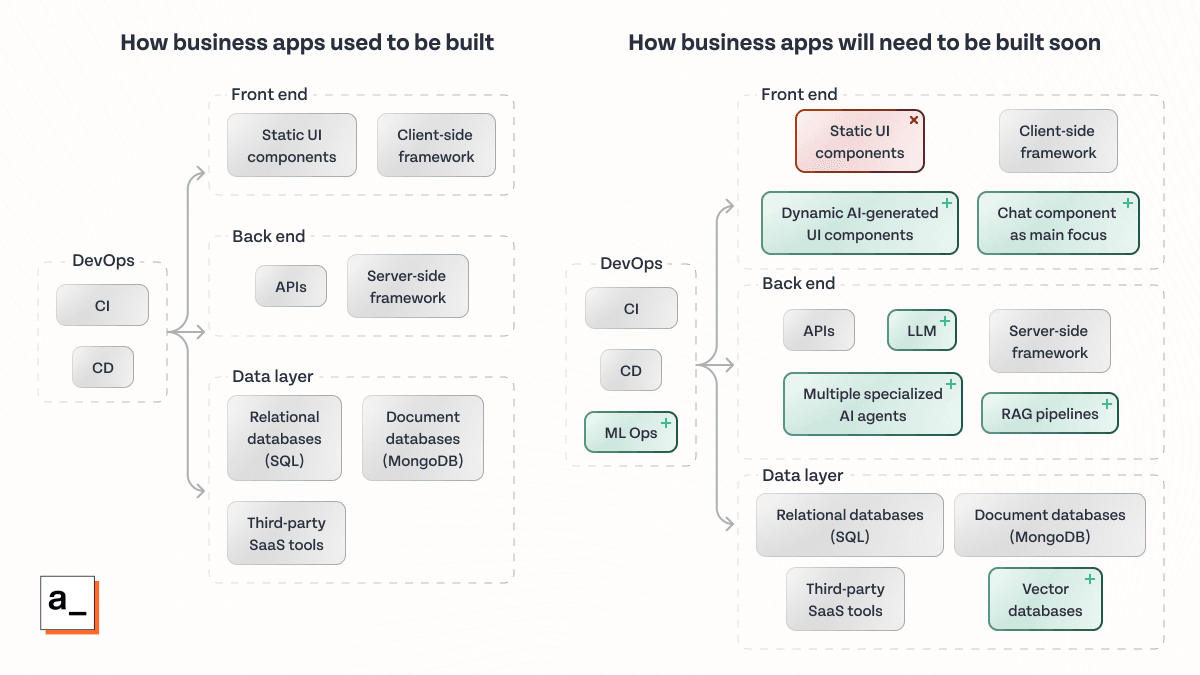
This new AI tech stack builds on the existing web stack, but at the same time it’s significantly different. There are several key components that need to be added on the front end and the back end to support this AI-centric functionality.
Large language models
Large language models (LLMs) are the new critical piece of technology that enables modern-day AI. They are AI systems intended to model human language. Having been trained on vast amounts of text, they have one job: predict the most likely next word given all the prior words. As LLMs have been improving generation after generation, they’ve recently reached the point (with the emergence of tools like ChatGPT) where unexpected, seemingly intelligent behavior has emerged. This has opened up a whole new frontier for AI applications.
Chat and other UI components
Chat interfaces (in which you ”chat” with an AI assistant that then performs actions on your behalf) will become the central point of interaction for many applications. It’s important to make sure that you implement chat and other UI components so that they are optimized for LLM usage. One specific requirement is support for data streaming, so that users can chat with their AI assistants in real time without having to reload the page or wait for entire conversations to display.
RAG pipeline
One major issue with LLMs over the past few years is that they might not have been trained on the data necessary to answer a user’s question, so they don’t actually “know” the answer. RAG pipelines have emerged as the major solution to deal with this problem.
RAG stands for “retrieval-augmented generation.” This means that applications can retrieve relevant data and feed it to the LLM alongside the user’s prompt to augment the quality of the response. Here’s an example:
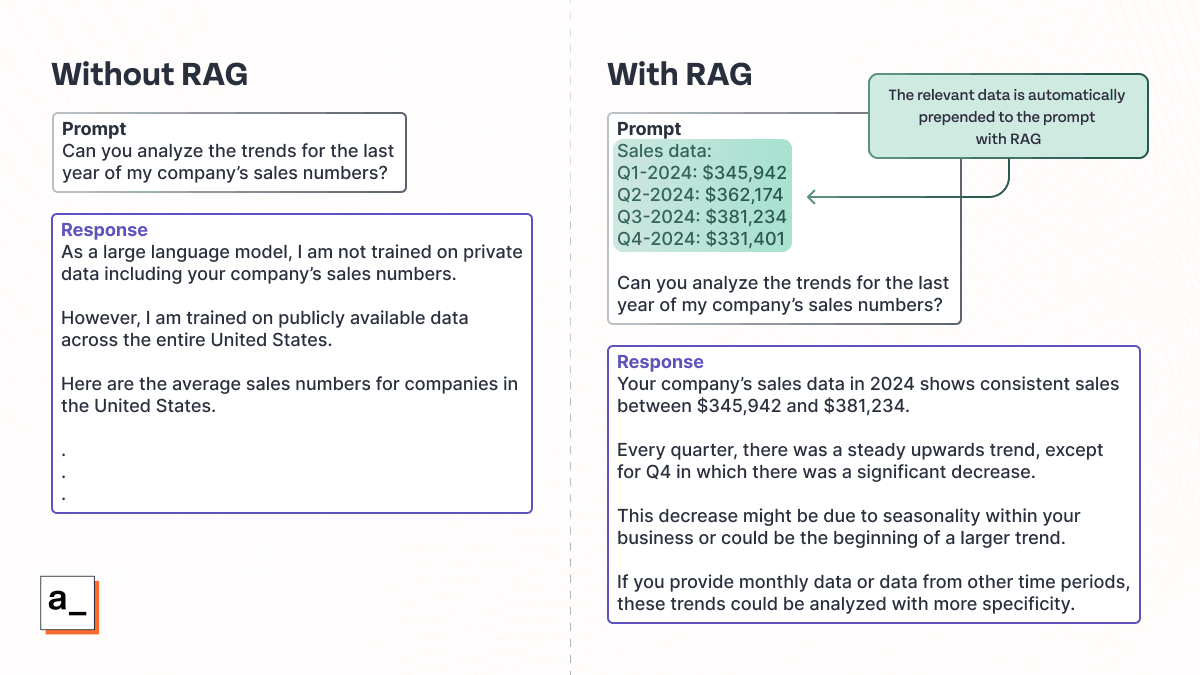
Max in sales asks his AI application to identify trends in the last several quarters of sales data. The LLM behind the application, however, was not trained on this data (both because it post-dates the training of the LLM, and also because Max's employer doesn't want proprietary business information shared with the LLM). This makes it impossible for the AI app to complete the request.
With RAG, the relevant sales data can first be queried from the sales platform and then prepended to the prompt sent to the LLM. The RAG process is automatically implemented in the application, so Max can just start asking questions. The LLM then has access to the required data, and can process it and discard it when it's done, keeping data securely in the sales platform where it belongs.
Traditional data sources (files, relational and document-based databases, APIs)
Because you may not want to share your internal proprietary data with public, third-party LLMs, your traditional data sources (including files, relational and document-based databases, and data retrieved from in-house and SaaS APIs) aren't going away anytime soon. AI will not make these obsolete. Having reliable tools to store data of different types will be just as important as ever — whether that’s in rows and columns with relational databases or more customizable JSON formats with document databases.
Vector databases
Alongside traditional databases, a new type of database has recently emerged that is critical to RAG. These are called vector databases or embedding databases and they are necessary for RAG to work properly. These databases store chunks of text represented as vectors, so that the similarity of two chunks of text can be calculated mathematically and the most similar chunks of text can be returned.
In other words, vector databases do math with the meaning of words ("dog" with "canine"), rather than just looking for exact string matches ("dog" with "dog"). In a business scenario, a RAG pipeline could query a vector database that contains a company's HR policies, find everything related to vacations, and then pass that to an LLM to answer staff questions.
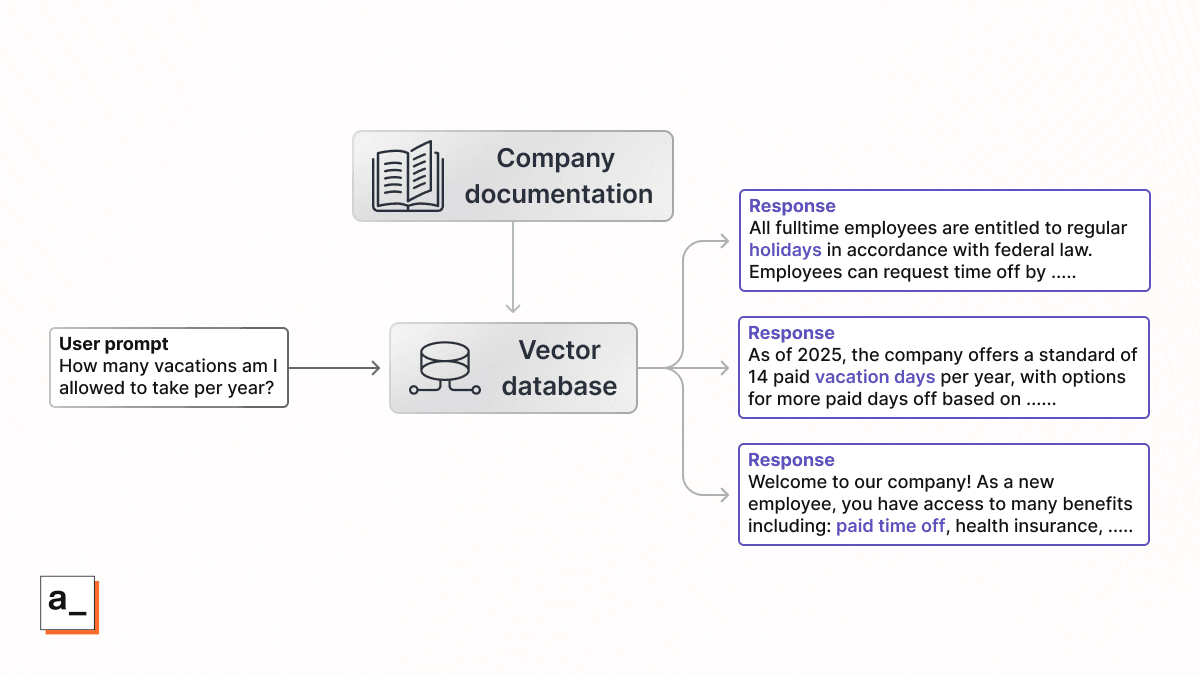
Chunks of text from throughout internal documentation can be loaded into a vector database. Then when certain prompts are queried in the database, the most semantically similar chunks of text can be retrieved from the database. Notice that it still works even if the exact words do not appear in the response text (“vacation days” is semantically similar to “paid time off”).
AI agents
RAG will be able to handle many use cases when it comes to answering questions, but there may be some requests that are more complicated to solve. In particular, these could be problems that require multiple rounds of trial and error and interaction with other tools. In these cases, AI agents can be ideal.
AI agents exhibit much more autonomy than traditional AI tools. They are programmed to interact with other tools (like search engines, calculators, and SaaS platforms like Salesforce or Zendesk) through well-defined APIs to accomplish objectives. Agents can plan out steps, execute those steps, then continue to adjust the plan through trial and error by adjusting their own queries.
For example, an agentic AI may be tasked with finding a room in the hotel where a conference is being held. If it finds no rooms are available for the conference date on its first try, it can broaden its search to hotels in the same neighborhood — all without the user having to manually intervene to adjust the initial query until the agent can find a suitable solution.
These agents can also go beyond interacting with other tools through pre-written APIs. They can write their own code to create their own queries, execute those queries, and try again if the response fails. This allows the LLM to access data by automatically generating code on the fly through trial and error without you having to program the queries in advance.
Figuring out how AI agents can best improve your workflows (and how to prevent them from taking unintended actions or accessing data they shouldn't) will be challenging as their capabilities are rapidly evolving. Reducing the scope for each individual agent is key to both limiting their reach and getting the most out of them — the fewer tasks each agent has to do, the better it can be at each one (just like your human team members)!
In the future, “adding new functionality” to the app might consist of adding a new agent that specializes in a certain kind of task. For example, an expanding support team may create different support agents for each of its products, with a "receptionist" agent who directs queries to the relevant agent. When a new product is released, a new agentic AI can be created for it.
Role-based access control (RBAC)
LLMs that integrate deeply into the web stack bring new security vulnerabilities. In order for an LLM to give useful and accurate answers, it has to have access to company data. But at the same time, it needs to be aware of which users should be allowed to access that data rather than just mindlessly answering any question that somebody asks. For example, if a user asks, “What is employee X’s salary?,” the LLM should not respond with the actual answer unless the user is privy to that information as part of their job role.
This is another reason why RAG is so critical: by implementing role-based access control (RBAC) at the database or API level, and then using the current user’s authorization to retrieve data before passing it to the LLM, you don't have to worry about the LLM disclosing information it shouldn't. Even if a nosey user tries to trick the LLM into ignoring its rules and disclosing sensitive information, it can't share what it doesn't know.
You must also consider how LLMs are handling personally identifiable information (PII) within your tech stack and which external systems you’re comfortable exposing that data to. This includes assessing:
The exact information you are feeding to public LLMs like OpenAI / Cohere
Whether you are effectively stripping out sensitive information before sending queries to public LLMs
Whether it's necessary or practical to leverage smaller, self-hosted LLMs for handling sensitive data
Quality control measures
LLMs also pose a unique and novel quality control problem that did not exist before. LLMs can only generate responses based on the probability of the two words being next to each other in the current context; they do not understand the meaning behind what they’re writing (this is the reason you’ll sometimes see LLMs fail at simple math problems). This inherently makes them less deterministic and harder to test than conventional algorithms.
For this reason, you will likely need ongoing human-in-the-loop (HITL) processes, which in addition to making decisions in critical workflows, can help ensure the quality of the outcomes your AI tools provide. It’s critical to track your LLM’s responses (both during testing and production) and build out other admin interfaces so that humans can manually look at the LLM responses and judge them on different metrics.
You can also build LLM evaluators (judge agents) into your automated unit tests by giving agents a few criteria to judge the quality of the responses from other LLMs. This can have a significant effect on both speed and quality of LLM training and usage, but human evaluators with a thorough understanding of your data, processes, and business should always be involved at each stage to sense-check the output.
A foundation for your AI toolchains
Hopefully, at this point, it's clear that the web application functionality of the future needs to be supported by a far more complex architecture than what exists today. However, this AI tech stack is highly technical and effort-intensive to implement yourself, which makes it impractical for the vast majority of businesses. Instead, it makes sense for application platforms to do the heavy lifting to put this infrastructure in place so that others can just use it and focus on their custom functionality for their own business.
After all, low code platforms exist to make it easier to build applications with current architectures. Given that the new AI-based architectures will be far more complex, the argument for low code becomes even stronger. But low-code platforms with most (or all) of the key components are missing today.
That’s why we're attacking this problem head on to integrate the key functionality within Appsmith to power the next generation of AI-based web applications. We've implemented some key functionality already with our natively supported Appsmith AI datasource and human-in-the-loop (HITL) components in Appsmith Workflows.
Appsmith users are already benefiting from functionality like this to power their AI apps. For example, Funding Societies has successfully built an AI assistant to automate 50% of customer support and loan processing work. They then used Appsmith to rapidly build interfaces for human users to manually verify and improve their AI assistant’s behavior — all while maintaining a 100% satisfaction rate.
This is an important proof of concept for AI in applications, which is why we’re busy implementing the rest of the features to keep us at the forefront of AI app development. You can always reach out if you have any questions about how Appsmith could help power your AI business apps.


